Important Steps of Geodata Processing
May 5th, 2021 | by Andreas Richter
(10 min read)
Without data there is no simulation and no operations. In our feature about Geodata in Simulation we already described the different components of a simulation, their data requirements, and that it is important to have only one master data lake. But we all know that there is no “one size fits all” data source. Thus, let’s talk about the processing steps of geodata to fill a data lake.
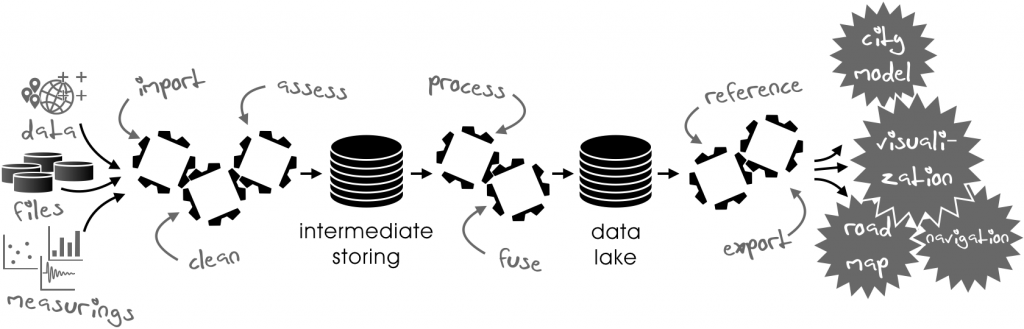
We will talk about the following processing steps:
- Importing
- Cleaning
- Assessing
- Processing
- Fusing
- Storing
- Referencing
- Exporting
For all components of a simulation or for the operations of the system, we need various data. The traffic area, for example, consists of the road surface, lanes, markings and infrastructure, but also vegetation, terrain and buildings, their structure and material, energy networks, airspace etc. can be important for recreating the environment. All these data are coming from different data sources because different stakeholders host and maintain different useful data.
If data are collected once, they are more or less immediately outdated. If we deal with, for example, quality of road marks, it could be the case that a road mark disappears relatively fast. Also road signs could vanish by drunken or frustrated road participants. Vegetation or buildings are more stable but could quickly change in their appearance. Therefore, it is also worth to think about recurring measurements of the same data to keep them up-to-date. And it makes sense to have them somehow loosely coupled to be able to update one part (road signs) even if we cannot update another part (road layout). Now, let’s go into detail.
Importing
Integrating new data sources or updating existing data starts with the import. This has to be implemented per data format and data source, respectively, in order to meet all technical boundaries. We are just talking about the import itself, everything else comes later. The import can be fine-tuned to the data collection system because it won’t change. Only “time in year and day” can vary the data. The constancy of data gathering makes it easy to fully automate the importing process and to carry it out in full-shift operation.
Cleaning
First, the loaded data has to be checked in order to remove glitches and outliers. Again, if we know the collecting data sources very well, we can also adapt to their characteristics. This step has to be done per data source and will increase the data quality from the beginning. Second, the raw data may have to be adjusted by modeling accuracy in some cases (approximate and interpolate). Third, it may help to convert all data using the same coordinate projection to avoid ambiguousness in the processing later on.
These steps depend a bit on the designated data lake and its required accuracy because sometimes it is too time-consuming doing these adaptions during further processing steps on-the-fly. The cleaning process can be automated as well but a final review and quality approval remains mandatory.
Assessing
Every data source has to be evaluated regarding the provided quality. This is because every source is providing a different precision and level of detail, and its data is of different age. On the one hand, especially data derived from sensor networks, e.g. floating car data (FCD) from vehicle fleets, may be less accurate than the data obtained by a calibrated measuring vehicle. On the other hand, data from vehicles fleets are coming in day-by-day, whereas a specialized measurement may be feasible only once a month or even less often.
Also within a single kind of data source, assessing can be necessary: A vehicle fleet can consist of differently equipped vehicles and where most of them use only few and cheap sensors and generate a lot of noisy data with a reduced coverage, other vehicles will have more and more capable sensors to provide better-quality data. You can use the fewer data from the better equipped vehicles to verify the huge amount of data of the less fitted vehicles. The same with cadastral data: One stakeholder might use highly accurate, differential geodetic measurements to locate his entities, where another uses just a simple, handheld GNSS tracker to acquire a position (without reference station or post-processing of errors).
The process of assessing can be automated per data source as well, especially if you have ground truth sample data at hand for verification. Sometimes it is worth to get, for example, a fixed point reference data set for verification. The results of the assessment can be stored as metadata because they can help to decide how to prioritize the data fusion later on. For example, the road description format OpenDRIVE offers the possibility to provide brief information about the accuracy of its modeled (geo)data and the processing steps applied.
Processing
More information can be derived from the imported and cleaned data after processing rather than from direct use of raw data. Laser scan raw data, for example, can be used to calculate the diameter of tree crowns and tree heights at the time of measurement, so you do not have to rely on cadastral data that is only updated once a year. Aerial images can be used to determine the location and quality of road marks for huge areas without operating a big fleet of measuring vehicles. The drawback is that sometimes aerial images are not precise enough to use the derived data directly. But aerial images can be improved in this aspect by geo-rectifying them with a set of ground-truth reference points. In the end the derived data gains accuracy as well.
But sometimes data also have to be adapted for usage in subsequent processing steps. Information about buildings can be very detailed and include protrusion and niches, for example. Sometimes it is necessary to remove such details in the first place and to re-create building models in a procedural way in order to comply with further processing steps. On occasion, data have to be transformed into a different data format. Taking again OpenDRIVE as an example, as road description format it uses a mathematical approach to describe the road using a functionally continuous reference line whereas cadastral formats prefer modeling through discrete coordinates with an area-driven concept using fewer logical correlation to describe the actual traffic area. To combine the traffic area with a terrain model and building footprints it is better to have a discrete twin of the road description at hand. Format transformation is a science in itself (esp. the data formats) and will be a story we will cover in another feature.
Nevertheless, even the data processing can be automated. This is true in particular when the data source with its data semantics is not changing and the structure of the data stays the same. If any of these changes, processing algorithms have to be adapted.
Fusing
Different data sources have to be fused to obtain an overall representation. For example, a road environment description consists of point information as well as of vector-based cadastral data derived from mobile mapping and aerial images. These different data have to be merged despite their temporal and spatial differences. For the fusing process, results of assessment are useful to select the best source as the ground truth for all other sources. This selection has to be done for each crucial element.
The fusing of data is the most challenging part of the whole process chain. Especially if various and many heterogeneous data sources are necessary for further processing, the fusing process has to be adapted consistently. This is because the used sources are usually not providing data updates at the same time, or, sometimes even no data are available at all. Therefore, the selection of the ground truth may change as well. Information that is only loosely related to other data (e.g. data about urban parks) can easily be incorporated into the road environment description, whereas it is more complicated to accomplish this with data which already represent a fusion of different data sources (e.g. complex road infrastructure because it is mostly maintained by different stakeholders with respect to street lighting, traffic lights, signs and poles/masts).
This rational leads to a multi-step fusing process. The more information is related with other data, the more complex the fusion process is. As a consequence, for example, information about road infrastructure, barriers and furniture, that might change their position and type more often, should be separated from the topographical description of the built road. As a result it is possible to update the road infrastructure layer without taking many dependencies into account. The fusing of the road infrastructure, furniture and vegetation with the topographical road description can be performed during the export process. With the fusion it is still possible to perform necessary spatial corrections if road infrastructure etc. does not fit to the road layout completely. Performing this correction “on demand” and not having it stored in the data renders the revoking of a correction in an outdated road description dataset obsolete during the update process .
This fusing feature is essential if data sources have to be replaced. It could be the case that one data source (e.g. aerial images) is no longer available but extensive cadastral surveying becomes available and affordable.
Storing
The cleaned, processed and fused data have to be stored somewhere and somehow. For this purpose, straightforward and open description formats should be used. They are implemented in corresponding geographic information systems (GIS).
The typical data are too diverse, thus specific strategies for storing and processing are necessary. For example, aerial images and elevation models in raster data format are stored differently from cadastral information, which is modeled as vector data. Further, information about the road environment may be stored with mathematical, continuous geometry representation – as done by certain road description formats – or with discrete geometry representation. Additionally, accuracy differs from centimeters for road description to meters for elevation models. As a consequence, our data lake just describes a bundle of distributed databases composed in a federal hierarchy.
A crucial point is to link the data. Relating as much information as possible directly across different database components is highly desirable. Thus, domain-specific data formats should be avoided because they are optimized for their specific use case, only including the problem of implicit representation of certain features. Straightforward and open description formats should be preferred which can be mapped to common geometrical elements with context information stored as attributes. Utilizing simple features in 3d (Point, LineString and Polygon) to comprehensively model the road environment builds the basis to use a data lake in a versatile manner. Using a simplified data model for objects allows a detailed modeling of roads and their setting by relations. The utilization of simple features enables the processing of data in GIS and related applications, benefiting from well-established technology. With the help of automated conversion, different and very specialized output formats can be provided for domain-specific use while simplified elements are translated into complex representations with their required spatial precision.
Versioning of data plays an important role as well, especially if the data are describing traffic or energy flows. It can later be used for analysis of progress and can feed simulations to better evaluate the (temporary) impact of, e.g. construction sites. This is done by either storing different temporal versions of the same data layer as one consistent dataset or by storing corresponding elements in multiple versions over time. They are still linked to related elements in different temporal versions.
The data storing in general is fully automatable. The data to be stored are known well, as well as the storage format. Therefore, implemented once it can be re-used again and again.
Referencing
Using location, referencing is an important part of the processing because, a “world format” for the description of every piece of information does not exist. To meet the different requirements of stakeholders, reasonable references have to be established. An example could be power supply infrastructure related to road environment in order to evaluate the impact on traffic flow due to construction activities. You could also incorporate complex building information modeling (BIM) without importing it entirely into your data lake by just including the building footprints directly and linking each building to its more detailed model in the referenced BIM data source. Thus, you can access the model’s actual data if necessary and avoid dealing with the complexity if not necessary.
The linkage can be stored as additional attributes in a data set itself or as additional data layers in a specific description language. Depending on the use case of each particular set of geodata, it may either merely list and link to additional data in a catalogue service (e.g. a Catalogue Service for the Web (CSW)), or it is implemented as a federated database management system (FDBMS), or, of course, as a combination of both. Additionally, location referencing enables mapping of elements from one map to another and can also be applied if a source element does not explicitly exist in the target map.
Exporting
Gathered and processed data have to be exported in different data formats to be used as, for example, road lane information for automated driving or 3D visualization for decision making of a new bicycle lane layout. Simplified road network data can be used for navigation. It is important that every export which is based on the same data set from our data lake does not export ambiguities. Accordingly, every target format requires the implementation of its own exporter to avoid loss of information and accuracy along the downstream conversion chain. Specific requirements for the target format should be implemented in the export and not in the previous data processing because, if “suddenly” a second export format is required, like having OpenDRIVE for development of driver assistant systems plus wanting to implement Navigation Data Standard (NDS) for operating driver assistant systems, you do not have to re-convert one complex format into another one and vice versa. Converting between domain-specific, complex data formats will almost always be lossy, introduce numerical challenges and lead to restricted flexibility regarding incorporation of future requirements. This makes a solid, simplified data lake design even more important.
The export can run fully automated as well, like the data storing, because used data and formats are well-defined.
Summary
We have seen that the common input–process–output model includes a lot of specific steps. It is necessary to spend time on defining every part because each one contributes a useful asset to the data. If you design one processing step poorly you will pay for it in the subsequent steps! The most complicated steps are the data fusion followed by the processing itself. They are the least automatable and might need constant adaptation.
Final question: Doing it once or doing it repeatedly? Often we will need updates of our data and you will run the processing tool chain again and again. Therefore, it is necessary to think about a modular (for re-using and adapting) and data-set-driven tool chain that can be automated as much as possible.
Acknowledgement
This feature is based on parts of the journal article “Towards an integrated urban development considering novel intelligent transportation systems“. The journal article also brings together different stakeholders and the all-embracing data lake. We will talk about the advantages of utilizing one data lake for different stakeholders as well. Stay tuned on GEONATIVES.org!